
들어가기
현재 개발중인 모각코 플랫폼은 같은 모각코에 속한 참여자들 끼리 모각코 온도(좋아요,싫어요)를 높이고 낮춰야하는 요구사항이 있습니다.
참여자들이 동시다발적으로 온도를 높이고 낮추려한다면 동시성 문제를 피할 수 없습니다.
문제 상황 파악하기
먼저 동시성의 정도를 파악해야합니다. 동시성의 정도를 파악하는게 불가능한 경우도 있고 가능하더라도 정확하게 예측하기란 어렵습니다.
실제 기업들은 모니터링과 통계정보를 통해서 어느 정도 분석을 하는 것 같습니다.
모각코 온도를 높이고 낮추는 오퍼레이션은 같은 그룹에 속한 참여자들 끼리만 가능하도록 설계돼있습니다.
한 그룹은 최대 15명까지 수용이 가능하도록 돼 있어 동시성이 높은 상황은 아니라고 판단이 됩니다.
이러한 상황에 적합한 해결책을 찾아보려 합니다.
비관적락
비관적락은 데이터베이스에서 SELECT ~ FOR UPDATE 구문을 사용하는 것입니다.
JPA를 사용한다면 간편하게 어노테이션으로 작성해줄 수 있습니다.
Exclusive Lock (읽기 X, 쓰기 X)
@Lock(LockModeType.PESSIMISTIC_WRITE)
Shared Lock (읽기 O, 쓰기 X)
@Lock(LockModeType.PESSIMISTIC_READ)
비관적락은 일단 충돌이 발생하면 락을 획득하기 위해서 대기합니다.
비관적락은 확실하게 동시성 문제를 해결할 수 있습니다.(데드락 발생은 논외)
하지만 일단 비관락은 선행트랜잭션이 락을 잡고 있다면 후행 트랜잭션은 일단 대기해야합니다.
문제는 데이터베이스 커넥션을 잡아 놓은 채로 대기해야한다는 점입니다. 이런 트랜잭션들이 동시다발적으로 생성된다면 성능도 안좋아질 겁니다.
물론 15명 정도의 동시성이 예상되는 문제에서 크게 성능저하는 없을거라 생각되지만 최악의 상황을 가정했을 때 조금 더 좋은 방법을 찾아보고자 합니다.
Message Queue
메세지 큐는 높은 트래픽이 발생했을 때 대기열(Queue)를 사용해서 메세지를 발행하는 쪽(Publisher)과 메세지를 소비하는 쪽(Consumer)을 서로 분리시킬 수 있습니다.
컨슈머를 구성할 때 싱글 스레드 기반으로 설정해준다면 대기열에서 메세지를 1개씩만 꺼낼테고 이는 동시성을 제어할 수 있는 좋은 방법입니다.
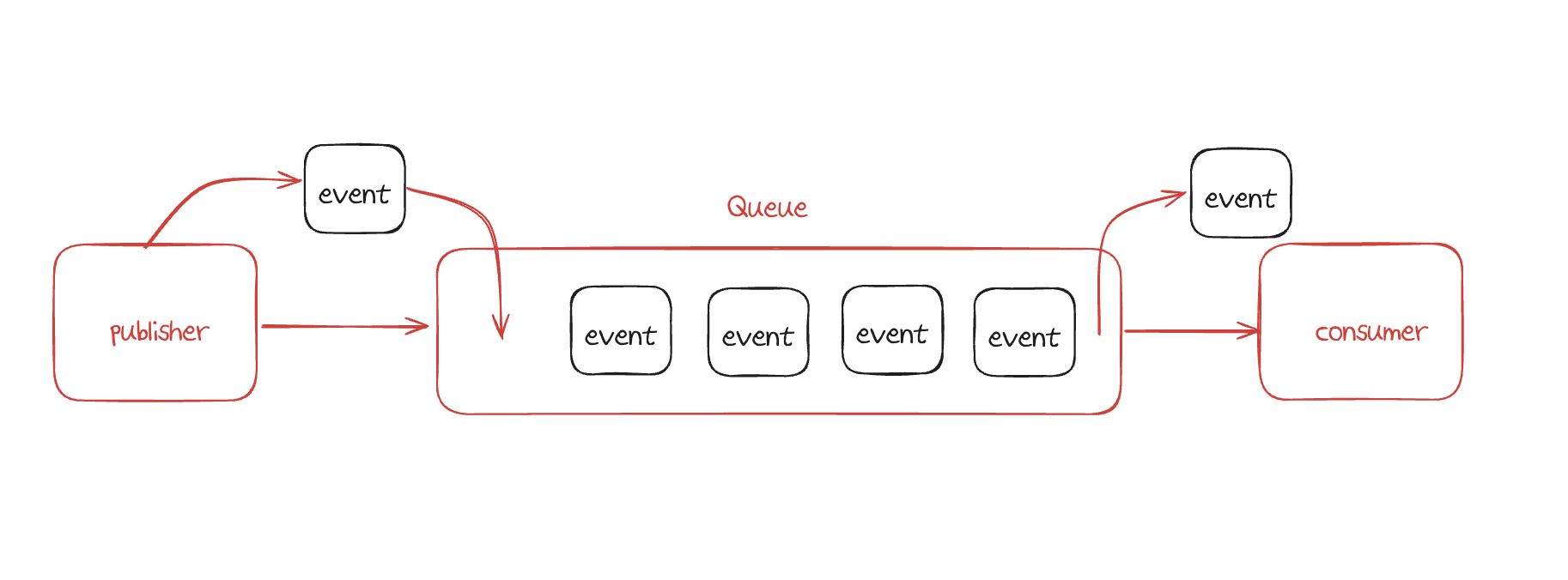
또한 순차적인 처리도 보장해줄 수 있어 실제 기업들에서도 많이 사용하는 것 같습니다.
RabbitMQ나 Redis의 List, Stream, Sorted Set을 이용하면 위에서 언급한 대기열을 만들어 줄 수 있습니다.
실제 배달의 민족, 올리브영은 대기열을 도입해 문제를 해결한 사례가 있습니다.
Redis Sorted Set
Redis Pub/Sub & List
Redis Pub/Sub을 활용한 쿠폰 발급 비동기 처리 | 올리브영 테크블로그
올리브영에서 쿠폰 발급 프로세스를 어떻게 개선 했는지 알아봅시다.
oliveyoung.tech
현재 아모르각코도 알림 발송을 위해 RabbitMQ를 도입했고 캐싱을 위해 Redis를 도입했지만 낮은 동시성 문제를 해결하는데 사용하기엔 오버엔지니어링이라는 생각이 들었습니다.
큐에 넣고 빼는 작업과 같이 네트워크 I/O를 발생시키는 것이 비효율적이라 판단했기 때문입니다.
Redis 분산락
분산락도 동시성문제를 해결할 때 자주 등장하는 기술 중 하나입니다.
Redis의 분산락은 이름에서 그 의미가 잘 드러나듯 분산된 환경에서 하나의 잠금을 획득해야할 때 적합한 기술입니다.
예를 들어 id가 1인 회원에 대한 잠금이 필요한 상황에서 id가 1인 데이터가 레디스의 여러 노드에 걸쳐 분산돼 있는 경우를 생각해봅시다.
하나의 노드에서만 잠금을 획득한다면 다른 노드에 가해지는 수정/삭제는 데이터의 정합성을 해치게 됩니다.

일반적으로 위와 같이 레디스의 노드가 여러개인 경우 분산락을 사용한다고 하지만
아래와 같이 레디스 노드가 1개이고 API서버가 여러개인 경우도 분산락을 걸어줄 수 있습니다.

세션 클러스터링과 비슷한 그림입니다.
모각코 온도에 적용한다면 레디스에 회원의 pk값을 key로 설정하고 value를 boolean값으로 두어서 해당 key를 잠금 객체로 사용하게 할 수 있습니다.
실제 현업에서 레디스를 단일 노드로 사용하는 것은 SPOF(Single Point Of Failure, 단일 장애 지점)을 유발해 쓰이지 않아 위와 같은 구조로 잘 쓰이는 것 같지는 습니다.
Lettuce vs Redission
스프링에서 공식으로 사용하는 레디스 클라이언트는 Lettuce지만 분산락을 사용할 때 Redission이 자주 언급됩니다.
분산락 사용에서 주된 차이는 Lettuce는 스핀락, Redission은 Pub/Sub 기반으로 작동해 부하가 적다는 점입니다.
낙관적락
낙관적락은 충돌이 많이 발생하지 않을 거라 판단하고 락을 잡지 않는 방법을 말합니다.
JPA에서는 Entity의 필드에 @Version 어노테이션을 통해 버전 필드를 관리하게됩니다.

데이터베이스에서 두 트랜잭션이 동시에 버전 1로 설정된 엔티티를 읽어옵니다.
트랜잭션 1이 조금더 빠르게 엔티티를 업데이트하면 Version은 2가 되고 트랜잭션 2는 아직 버전정보가 1이기 때문에 업데이트에 실패하게 됩니다.
이 방식은 비관락에 비해 부하가 심하지 않습니다. 커넥션을 계속해서 잡고있지 않기 때문이죠.
그런데 낙관락에서 업데이트에 실패하면 주로 재시도를 수행하게 되는데 이 재시도를 불필요하게 많이 수행하도록 설계하면 DB부하는 비관락보다도 심해질 수 있으니 주의해서 설계해야합니다.
아래는 제가 커스텀하게 만든 재시도 어노테이션 입니다.
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Retryable(retryFor = ObjectOptimisticLockingFailureException.class, maxAttempts = 4, backoff = @Backoff(delay = 300, maxDelay = 600, multiplier = 1.2, random = true)
)
public @interface OptimisticLockRetryable {
@AliasFor(annotation = Retryable.class, attribute = "recover")
String recover() default "";
}
ObjectOptimisticLockingFailureException이 발생한 경우 최대 4번을 재시도하게 설정했습니다.
backoff는 재시도 수행 후 다시 실패할 경우 다음 재시도 사이에 간격을 설정해줄 수 있습니다.
기본 지연 시간은 300ms, 최대 지연은 600ms 이고 random = true, multiplier = 1.2로 설정했습니다.
random=true가 가지는 의미는 첫 번째 시도가 실패하고 그 다음 재시도는 최대 지연 * 1.2 를 최대 값으로 가지고 최소 값은 300ms를 갖는 분포 사이에서 무작위로 딜레이를 설정하는 방식입니다.
이 방식을 지터 무작위 방식이라 하고 재시도 타이밍을 서로 엇갈리게 하여 총 재시도 횟수를 낮추고자 위와 같이 설정해주었습니다.

만약 무작위 재시도를 4회 이상 실패한다면 그에 대응할 Recover 메서드를 정의해 적절한 오류응답을 내려주기로 했습니다.
@OptimisticLockRetryable(recover = "temperatureRecover")
@Recover
public TemperatureResponse temperatureRecover(final Long groupId, final Long requestMemberId, final Long targetMemberId) {
throw RetryFailedException.retryFailed();
}
Recover 메서드는 실패한 메서드의 시그니처와 정확히 동일하게 작성해야합니다.
테스트
@Test
@DisplayName("멀티 스레드 환경에서 온도를 상승시킨 횟수 만큼 온도가 상승돼야한다.")
void increaseTemperatureConcurrencyTest() throws InterruptedException {
//given
Member requestMember = TestMemberFactory.createEntity();
Member targetMember = TestMemberFactory.createEntity();
memberRepository.save(requestMember);
memberRepository.save(targetMember);
Group group = TestGroupFactory.create(requestMember);
group.addParticipants(new Participant(targetMember));
groupRepository.save(group);
int threadCount = 15;
//when
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.execute(() -> {
try {
participantService.increaseTemperature(group.getId(), requestMember.getId(), targetMember.getId());
} catch (Exception e) {
System.out.println(e);
} finally {
latch.countDown();
}
});
}
latch.await();
//then
Member updatedMember = memberRepository.findById(targetMember.getId()).get();
Integer temperature = updatedMember.getMoGakCoTemperature();
assertThat(temperature).isEqualTo(threadCount);
}
위 코드는 총 15개의 스레드를 동시에 실행해 모각코의 온도를 상승시키는 코드입니다.
테스트 결과 총 31회 시도 끝에 모든 재시도는 성공했습니다. (초기 시도 포함)
결론
많은 해결책 중 낙관적락을 도입해 해결해봤습니다.
지금 문제상황은 동시성이 높지 않다고 판단했지만 또 다른 문제에선 동시성이 높고 순차처리까지 고려해야할 수 있습니다.(선착순 쿠폰, 티케팅 등)
그때 마다 적절한 해결책을 고민해볼 수 있는 좋은 기회가 됐던것 같습니다.
'Spring' 카테고리의 다른 글
| RabbitMQ Prefetch와 ConcurrentConsumer의 관계 (0) | 2025.01.05 |
|---|---|
| Hibernate ORM User Guide 오픈소스 기여 (0) | 2024.12.30 |
| 정렬 알고리즘 [선택정렬, 버블정렬, 삽입정렬] (0) | 2024.09.27 |
| Spring OAuth2 Client 흐름 개선시키기 (0) | 2024.09.14 |
| Google S2 (3) | 2024.09.11 |