
LinkedList
링크드리스트 자료구조 역시 이름에서 특징이 잘 드러난다.
링크드리스트는 노드라고 불리는 객체가 서로서로 연결된 리스트다.
아래는 자바의 링크드리스트의 노드 클래스다.
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
내부 클래스로 되어있고 하나의 노드엔 다음 노드와 이전 노드를 가리킬 수 있는 필드가 선언돼있다.
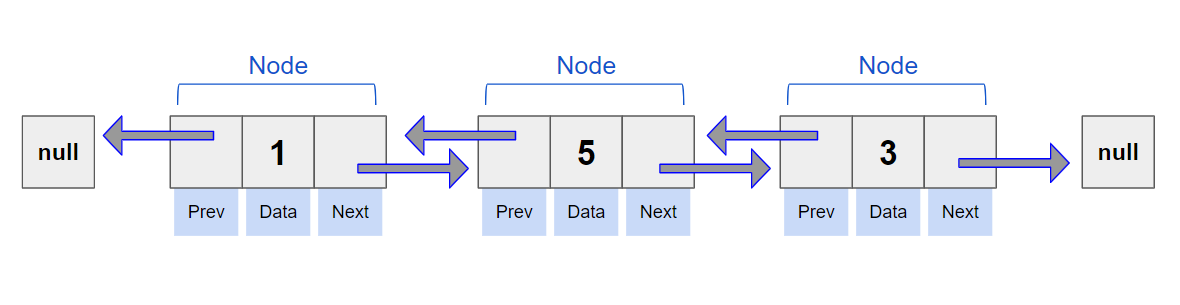
이렇게 노드는 각자가 서로를 참조하는 형태로 연결돼 앞뒤로 이동이 가능하다.
이런 형태를 Doubly Linked List(양방향 연결리스트) 라고 부른다.
왜 태어났을까?
첫 번째 이유
앞서 ArrayList의 큰 단점은 0번 인덱스에 데이터를 추가하려면 모든 데이터를 한 칸씩 뒤로 미는 연산을 수행해야한다.
삽입연산 한 번에 복잡도가 O(N)으로 꽤나 높다.
하지만 연결리스트는 새로운 노드를 하나 생성하고 참조 연결을 맨 앞으로 변경해주면 O(1)의 복잡도를 갖는다.
뒤에 추가하는 연산도 마찬가지로 O(1)이다.
자바의 연결리스트는 앞,뒤 노드를 필드로 들고있기 때문이다.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
*/
transient Node<E> first;
/**
* Pointer to last node.
*/
transient Node<E> last;
두 번째 이유
ArrayList는 배열크기를 가변적으로 변경할 수 있긴 하지만 그 전체 공간을 다 쓸지는 미지수다.
하지만 LikedList는 데이터 개수만큼만 노드가 생성되기에 사용하지 않는 공간이란 없다.
물론 노드라는 객체를 생성하는 비용이 있긴하다.
세 번째 이유 -> 흔한 오해
여러 책이나 강의를 통해 연결리스트가 중간에 삽입하는 연산이 매우 빠르다고 소개한다.
새로운 노드를 생성하고 앞 뒤 참조 연결만 변경해주면 되기 때문에 O(1)의 복잡도를 갖기 때문에 맞는 말이긴 하다.
삽입하는 연산 자체는 빠른것은 맞지만 연결리스트는 삽입할 위치를 찾아야한다. 이 복잡도가 O(n)이다.
따라서 전체 복잡도가 O(n)이다.
ArrayList도 자료를 추가하기 위해서는 데이터를 밀어야하기 때문에 O(n)의 복잡도가 추가하는 O(1)의 복잡도로
전체 복잡도가 O(n)이다.
결국 두 자료구조가 중간 삽입 연산은 성능이 똑같은 걸까?
성능 비교
성능 비교는 김영한 강사님의 자바 중급2편을 참고했다.
테스트는 루프를 돌며 ArrayList , LinkedList에 앞에 추가하는 연산, 중간에 추가하는 연산, 마지막에 추가하는 연산을 각각 5만번 수행했다.
int size = 50_000;
System.out.println("==ArrayList 추가==");
addFirst(new ArrayList<>(), size);
addMid(new ArrayList<>(), size);
ArrayList<Integer> arrayList = new ArrayList<>(); //조회용 데이터로 사용
addLast(arrayList, size);
System.out.println("==LinkedList 추가==");
addFirst(new LinkedList<>(), size);
addMid(new LinkedList<>(), size);
LinkedList<Integer> linkedList = new LinkedList<>(); //조회용 데이터로 사용
addLast(linkedList, size);

1. 앞에 추가
ArrayList - O(N) , 데이터를 뒤로 밀어야함
LinkedList - O(1) , 참조만 변경하면 됨
성능차이가 50배 이상 발생한다.
2. 중간 지점에 추가
ArrayList - O(N) , 데이터를 뒤로 밀어야함
LinkedList - O(N) , 삽입은 O(1)이지만 삽입위치를 찾는데 O(N)
이 결과가 조금 이상하다. 똑같이 O(N) 복잡도인데 20배가까이 성능 차이가 벌어진다.
3. 뒤에 추가
ArrayList - O(1), 마지막 인덱스에 추가하면 됨
LinkedList - O(1), 마지막 노드에 연결하면 됨
2번 테스트의 결과가 상이한 이유
첫 번째
배열은 연속적인 메모리를 할당받는다.
즉 자료가 모두 붙어 있어 접근성이 매우 높다.
반면 연결리스트는 다음 노드를 탐색한 뒤에 데이터를 찾을 수 있다.
두 번째
연속적인 메모리 할당은 CPU 캐시 히트율을 높일 수 있다.
하지만 연결리스트는 힙공간에 흩어져 존재하기 때문에 배열보다 캐시 히트율이 떨어질 수 있다.
세 번째
배열이 데이터를 추가하기위해 뒤에 데이터를 밀어내는 작업이 그다지 느리지 않다.
보통 배열에서 데이터를 한 칸씩 밀어내려면 O(N)이 걸릴 것이라 생각하지만 그렇지 않을 수 있다.
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
위에 Arrays.copyOf() 는 내부에 C언어로 컴파일된 native method가 있다.
이 메서드는 연속적인 메모리를 블럭 채로 복사하기 때문에 O(N)보다 성능이 좋을 수 있다.
계속 ~ 수 있다는 말을 쓰는데 JVM와 사용하는 하드웨어에따라 성능은 달라질 수 있기 때문이다.
LinkedList 그래서 별로인가?
앞에 추가,삭제하는 연산이 아니고서야 ArrayList보다 좋은 지표가 없다.
하지만 FIFO구조를 구현해내기엔 완벽한 자료구조다.
대부분의 연산이 앞쪽에서 발생하는 큐에 적합하다.
양방향 연결리스트이기 때문에 뒷쪽에서 추가,삭제가 발생하는 덱구조에서도 유용하게 쓸 수 있겠다.
'자료구조' 카테고리의 다른 글
| O(logN)을 보장하는 레드-블랙 트리 (0) | 2024.05.31 |
|---|---|
| 해쉬충돌을 해결하는 몇 가지 방법 (0) | 2024.05.31 |
| Set 자료구조가 검색이 빠른 이유 (0) | 2024.05.29 |
| ArrayList의 배열 리사이징 (0) | 2024.05.15 |